Coming at you with the 2nd episode of this series where I document my research project investigating semantic drift in Sanskrit. Today (or really whenever you're reading it), I'll be describing how I pursued my corpus construction, including data collection, organization, pre-processing. I'll tackle the Sanskrit-specific challenges (alluded to by the earlier entries) in a later post because that’s a whole different beast altogether.
The first step in this process is amassing all of the data. We have two options here:
- Take a trip to India and pore over the preserved ancient texts in libraries (fun, exciting)
- Download every file we can on online databases (boring)
Although Option 1 is appealing, we'll choose the second route since it's a bit more convenient as we're working with computers. And I guess you can stay at home and probably get better data.
I sourced my texts from GRETIL, or the Göttingen Register of Electronic Texts in Indian Languages. It's one of the largest open-access repositories of digital Sanskrit texts for academic inquiry. That said, it isn't perfect as texts come from different editors and researchers. This means discrepancies primarily in formatting and interpretations (different editors percieve things differently), which we'll look at very soon. But first, what do we need to download again?
Well, if you'll remember (assuming you read the case-study entry), I've split the literature into these four time periods:
- Vedic (1500-500 BCE)
- Early Classical Upaniṣadic (700-200 BCE)
- Epics (400 BCE - 400 CE)
- Śāstra + Sūtra (200 BCE - 500 CE)
This does not encompass all Sanskrit literature, it is a specific window researched from pages such as this to capture major linguistic and philosophical transitions.
Once I had downloaded texts and categorized them in their respective periods, the next step was cleaning and processing the data. As great as digital Sanskrit corpora are, they are messy and contain verse lines, editorial notes, metadata, page markers, and extra punctuation & unused symbols. We want to strip the files of all of this additional information so that only the Sanskrit content is fed to the model.
Thankfully, this cleaning (for the most part) can be quickly applied over millions of verses via Regular expressions, or Regex.
Regular Expressions
Simply put, a regular expression is a sequence of characters that defines a search pattern. We can use this for matching, locating, and manipulating strings.
The example below matches a word that starts with a capital letter and continues with at least one word character.
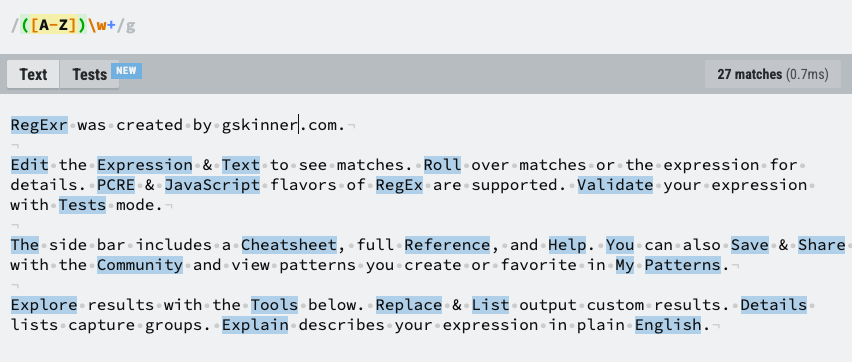 You can play around with regex here.
You can play around with regex here.
To remove all instances of editorial notes and some types of verse lines, I implemented the following regular expresion. This catches all bracketed content such as <1.1.1> or (yathā). It's now just a few clicks to replace all matches with empty strings or whitespace.
\(.*?\) | \<.*?\> | \[.*?\] | \{.*?\}
It wasn't all that straightfoward, however, due lots of inconsistencies across different files, but eventually after maybe 7 regex patterns and many iterations, I was left with raw Sanskrit text.
Other things
Deleting headers before the #text marker (if you're curious, download one of the .txt files on GRETIL, you'll see). Unicode normalization. Extra punctuation / symbols were eradicated as well, including *, @, =, -, ‘, “, .. Well, that was a short section!
Transliteration
Sanskrit digital texts come in multiple scripts and transliteration schemes such as IAST, Harvard-Kyoto, SLP1, or the occasional Devanagari. All text was standardized to IAST first for tokenization mechanics (stay tuned for my next post) and then finally converted to SLP1 to be fed into the model.
SLP1 was chosen for this task because it maps each Devanagari to a single, unique ASCII character (no pesky diacritics).
Conclusion
Thanks for reading! I'd love to hear your thoughts, suggestions, and questions - please do reach out.